The difference between data backup and data archiving, and why it matters to you
Data is your organisation’s most valuable asset – it’s paramount that you protect it.
If you are faced with large amounts of precious data which you will need to access in the future, it is imperative that you understand the importance in the use of a digital archive and not relying solely on a data backup.
Throughout this blog, I’ll explain the high-level differences between an archive and a backup, discuss the importance of treating data differently, share a real-life example of data loss, explore the options for creating a digital archive and share the questions you can ask solution providers to ensure that they meet your archiving needs.
Storage backup vs Digital archiving
When organisations create a long-term strategy for the archival of data, mistakes tend to occur when an individual involved in the process does not fully comprehend the differences between a backup and a digital archive. Assumptions that a backup will match the functionality of an archive are false and could result in data loss.
Fundamentally, a data backup is where a snapshot of your data is taken and stored elsewhere so that, if required, you are able to recover this data from a certain point in time (PIT). Typically, this recovery method is used in disaster situations, such as an incident of data deletion or corruption.
In the diagram below we’ve outlined an example of how a backup can work for an organisation. Typically, daily backups are kept for a certain amount of days, which are then replaced by weekly backups, which are then replaced by monthly backups. Businesses usually keep a number of daily and weekly backups at one time which are replaced on a continual basis.
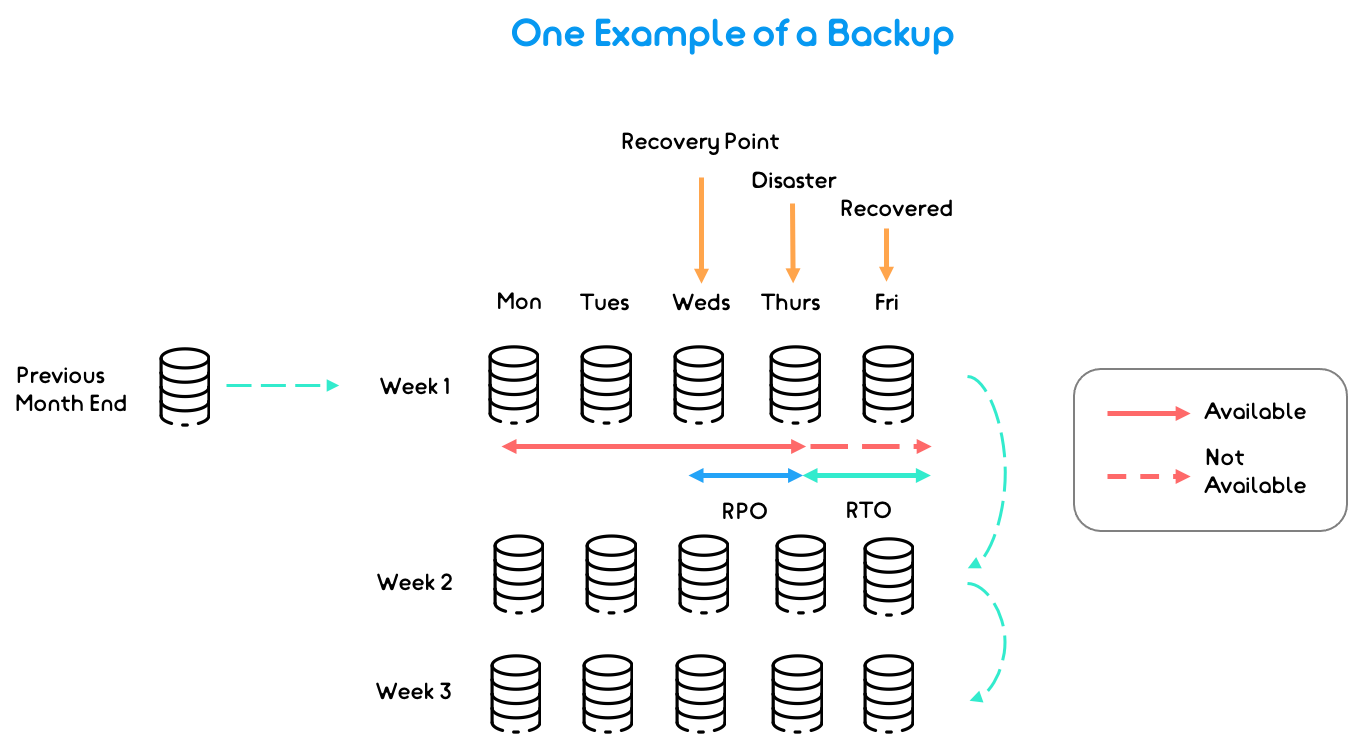
As you can see, when a disaster strikes data can be lost in a backup system therefore it is important to think about your recovery point objectives and recovery time objectives – we’ll cover this in more detail in the next section of the blog. Organisations must also complete ongoing checks and tests of their backups to ensure that they are not exposing themselves to ransomware – a malware that employs encryption to hold a victim’s information at ransom.
A data archive is an ongoing, managed environment that focuses on the preservation of your data. It goes beyond creating a copy and instead, focuses on the accessibility and re-use of your data – long into the future.
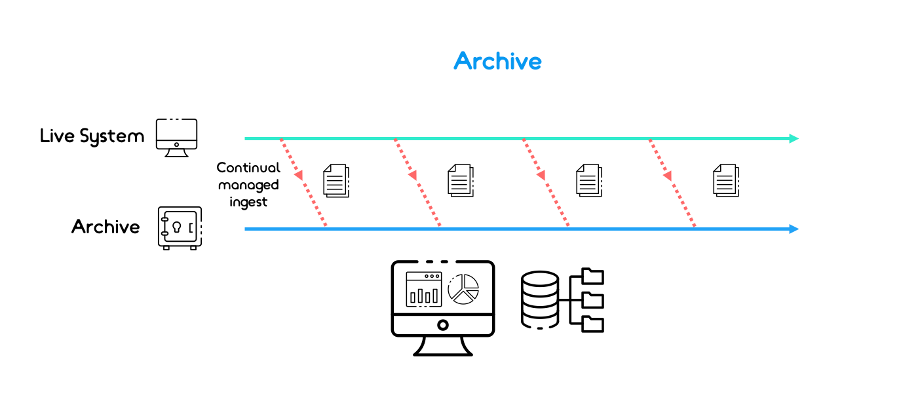
Relying on a backup for the purposes of archiving your data for a long period of time does not protect against data loss, corruption or from formats becoming obsolete. This is before taking into account the data being stored in such a way that it can be easily searched and retrieved if required. Examples of how this is managed within an archive can include leveraging metadata to improve searchability and maintaining preservation copies of files so they can be used and read long into the future.
Leaving your data in a live system long-term with backups running on a continual basis can lead to a lot of data being stored, opening you up to risks of data loss, excessive costs or data deletion.
The build-up of this data can also cause issues around data portability, a concept where users have their data stored in silos that are incompatible with one another thus subjecting them to vendor lock-in, once again opening your business to further costs.
Treating data differently
Another area that can cause real issue is when individuals involved in designing your archiving and backup strategy treat all data the same.
When it comes to your data there will be varying levels of retention and required accessibility, for example you may have files that have a 25-year retention, such as the eTMF in the life sciences industry, while other documents such as financial statements may require a 7-year retention. I’d also like to highlight at this stage that not all data may need to be managed in an archive, some documents such as marketing materials, you may be comfortable leaving within your live site.
When deciding on the best strategy for your organisation’s data, you’ll need to think about your Recovery Point Objective (RPO) and Recovery Time Objective (RTO). RPO defines the maximum allowable amount of lost data measured in time from a failure occurrence to the last valid backup. RTO is the downtime and refers to how long it takes to restore from the incident until normal operations are available to users.
Selecting a good backup provider is important. Selecting a substandard provider or one without the right safeguards in place can have a detrimental effect on your business. Remember that a backup tends to be operational while an archive focuses on long-term retention. Your archive and backup should work hand in hand.
To build the most effective strategy, you should ask yourself:
- What is the purpose of my data?
- Does it need to be maintained in an operational state, in a ‘live’ production environment, or does it need to be archived to preserve the data, years into the future?
- What are my recovery point objectives (RPO) and recovery time objectives (RTO)?
- What are my legal or regulatory requirements for retaining some/all of my data?
Once you have determined which data you require long-term access to, you should move this into an archive. That way you ensure the data’s preservation, rather than depending on a backup which can’t always guarantee the files’ accessibility long-term.
The real effects of data loss
Typically, backup technologies have a fairly high reliability rate for recovery but when you solely rely on an unverified or substandard backup provider and something goes wrong, it can have detrimental effects on a business. These could vary from reputational damage, fines or the requirement to repeat previous business activities to retrieve the data that has been lost.
Last year we released a blog called Whoops where’s my data? in which we shared a few high-profile examples of where data had been lost by the BBC, Pixar and NASA. More stories of data loss continue to emerge with some specifically highlighting the failings of backups and demonstrating why these are not always enough to protect your data.
Memorial University, Canada
In 2016, the staff at the Queen Elizabeth II library, Memorial University were undertaking routine maintenance which required power to the building to be cut and switched to a backup system. During this process, the backup system failed, and more than 70 terabytes of data were lost during this event.
Luckily for the university, physical documents and objects still existed but they had to begin the process of digitising these collections again, which can be very expensive and time-consuming. As you can see in this example, the backup failed to protect the libraries’ data.
Incorporating digital preservation strategies into your organisation and combining the creation of a long-term archive with a backup for your data can assist in alleviating the risk of data loss.
What are my options for building a digital archive?
Now that we have outlined the difference between a backup and an archive and looked at an example of data loss, you may be starting to think about your next steps and options for creating a data archive.
For all industries, when it comes to creating a data archive you have two options: building the archive in-house or working with a third-party solution provider.
(We recently wrote a blog which delves into this topic for drug sponsors and relates specifically to the archiving and preservation of the eTMF.)
When looking at new technology, IT engineers sometimes debate whether to build their solution in-house. The main benefit of this is the opportunity to own and build the solution around your organisation’s specific needs, offering more flexibility, however, this takes significant time, effort and skills because of the specialist nature of corresponding workflows, systems and integrations. The Total Cost of Ownership (TCO) of on-premise solutions, especially over time, is significant.
Furthermore, organisations risk having periods where they don’t have the requisite resources to sustain this approach, for example because of loss of staff or fluctuations in funding. Even large and well-founded institutions such as national libraries or international research facilities are increasingly choosing to opt for cloud hosted solutions.
To assist in the buy vs build decision, ask yourself: does your IT team have the capability to manage and access years and years of data, long into the future?
Choosing to outsource your solution could reduce that burden for them.
Questions to ask solution providers
Making the decision on whether to build your archiving solution in-house or work with a third-party isn’t always easy, but if you find yourself in this predicament, we’d suggest reaching out to third parties initially so you can understand the capabilities of their solution and compare this with your internal capabilities.
Outlined below are a list of questions and talking points we’d suggest you use when speaking to third parties so that you can better understand their solution and their business, and how this will align with your company’s data archiving requirements.
- What do you use to backup your system?
- What protections do you have in place to stop data being tampered with?
- How can you meet industry regulations?
- Does your solution enforce best practice approaches for good data management, such as FAIR and ALCOA+?
- Are you ISO 9001 and ISO 27001 certified?
- Will you store my data in multiple geographic locations?
- Do you have an exit strategy?
At Arkivum we are recognised internationally for our expertise in the archiving and digital preservation of valuable data and digitised assets in large volumes and multiple formats. If you’d like to learn more about how we have worked with other organisations to deliver a digital archive for their business contact us today.

Chris Sigley
Chris is the Chief Executive Officer at Arkivum. He joined the business in June 2020 to drive further growth across the business, both by capitalising on its established client base in higher education, culture and heritage and by gaining wider traction in sectors such as life sciences and pharmaceuticals, corporate, and scientific research.
Get in touch
Interested in finding out more? Click the link below to arrange a time with one of our experienced team members.
Book a demo